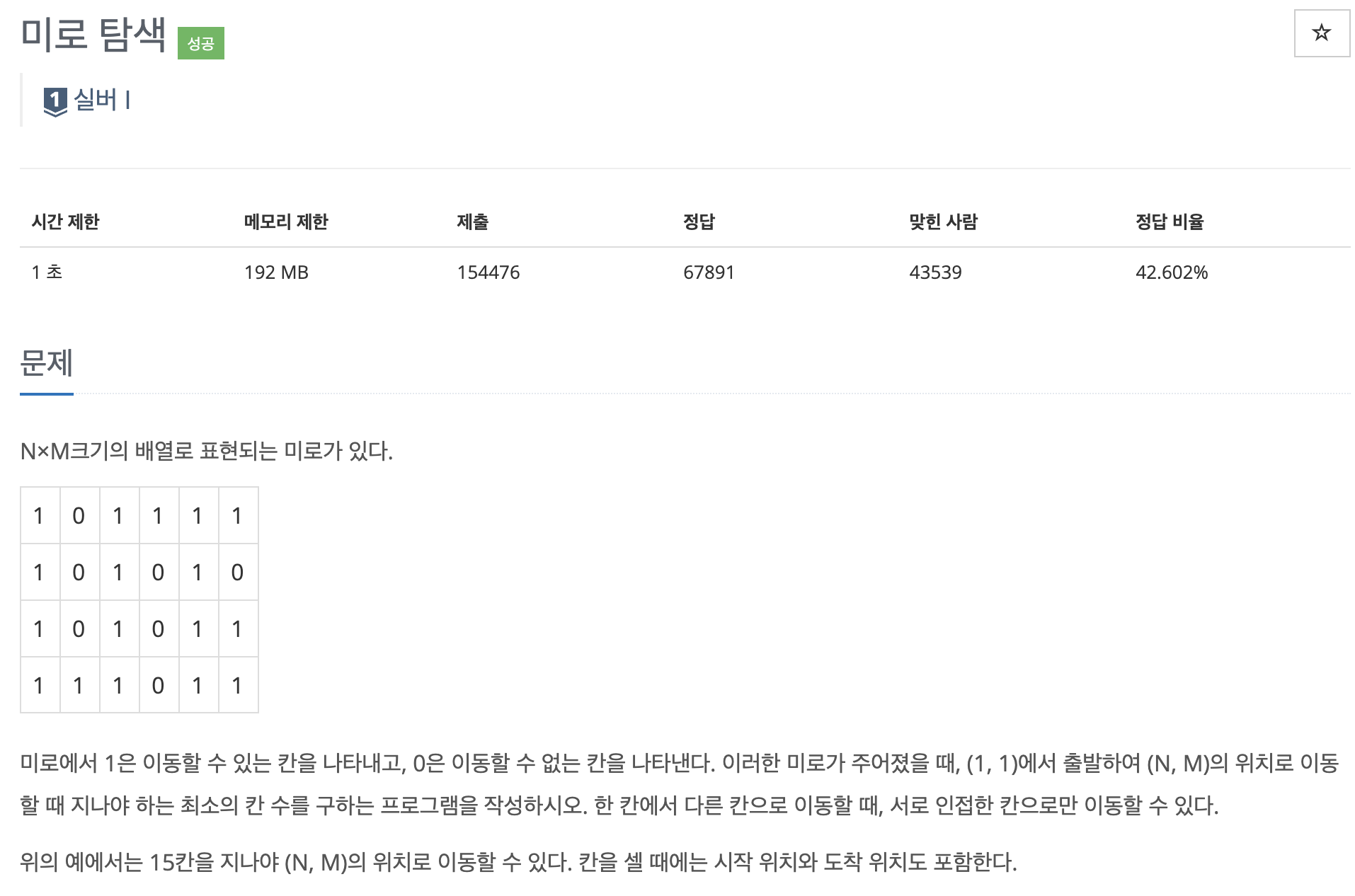
아이디어 : BFS, 큐
ChatGPT : BFS 알고리즘
BFS(너비 우선 탐색) 알고리즘은 그래프를 탐색하는 알고리즘 중 하나로, 시작 정점에서 시작해서 그래프를 한 층씩 모두 탐색하는 방법입니다. 즉, 시작 정점으로부터 가장 가까운 정점부터 방문하며, 같은 거리에 있는 정점들을 모두 방문한 후에 다음 단계로 넘어가는 방식입니다.
BFS 알고리즘은 큐(Queue) 자료구조를 사용하여 구현할 수 있습니다. 먼저, 시작 정점을 큐에 넣고, 큐에서 정점을 하나씩 빼면서 해당 정점과 연결된 모든 정점들을 큐에 넣습니다. 그리고 큐에서 다시 정점을 빼면서 그 정점과 연결된 모든 정점들을 큐에 넣습니다. 이러한 과정을 반복하여 모든 정점을 방문합니다.
BFS 알고리즘은 그래프의 모든 정점과 간선을 한 번씩 방문하기 때문에 시간 복잡도는 O(V+E)입니다. 여기서 V는 정점의 개수이고, E는 간선의 개수입니다.
BFS 알고리즘은 최단 경로를 구하는 문제나, 모든 정점을 탐색하는 문제 등에 활용됩니다. 또한, DFS(깊이 우선 탐색)와 함께 그래프 탐색 문제를 해결하는 경우가 많습니다.
파이썬 큐 자료구조
1. queue()
import queue
# 큐 생성
q = queue.Queue()
# 큐에 데이터 추가
q.put(1)
q.put(2)
q.put(3)
# 큐에서 데이터 추출
while not q.empty():
print(q.get())2. deque()
: deque(double-ended queue, 데크)는 파이썬에서 제공하는 자료구조 중 하나로, 스택과 큐를 결합한 형태의 자료구조임.
양쪽 끝에서 데이터를 삽입하고 삭제할 수 있음.
from collections import deque
# deque 생성
dq = deque()
# 데크 오른쪽에 데이터 추가
dq.append(1)
dq.append(2)
dq.append(3)
# 데크 왼쪽에 데이터 추가
dq.appendleft(0)
# 데크에서 데이터 추출
print(dq.popleft()) # 0
print(dq.pop()) # 3파이썬 split vs strip
split() 함수는 문자열을 분리하여 리스트로 반환하는 함수이고, strip() 함수는 문자열의 양 끝에서 공백을 제거하는 함수입니다.
1. split()
s = "1,2,3"
lst = s.split(",")
print(lst) # [1, 2, 3]2. strip()
s = " hello "
s = s.strip()
print(s) # "hello"문제 해결 과정
1. 시작점 좌표를 큐에 넣는다.
2. 큐에서 좌료를 get() 한다.
3. 해당 좌표로부터 4방위 탐색을 통해 이동할수 있는 칸 1의 좌표를 큐에 넣는다.
이때, put() 좌표에 해당하는 그래프의 값을 이동 횟수로 업데이트한다.
4. 큐가 빌 때까지, 위 1~3의 로직을 반복한다.
5. N, M 좌표에 해당되는 그래프의 값을 조회한다.
나의 답안
답안 1 : 데크 사용
import sys
from collections import deque
input = sys.stdin.readline
n, m = map(int, input().split())
graph = []
for _ in range(n):
graph.append(list(map(int, input().strip())))
# r d l u
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
que = deque()
def bfs(y, x):
que.append((y,x))
while que:
qy, qx = que.popleft()
for i in range(4):
gy = qy+dy[i]
gx = qx+dx[i]
if 0 <= gy < n and 0 <= gx < m:
if graph[gy][gx] == 1:
que.append((gy, gx))
graph[gy][gx] = graph[qy][qx] + 1
return graph[n-1][m-1]
print(bfs(0,0))답안 2 : 큐 사용
import sys
import queue
input = sys.stdin.readline
n, m = map(int, input().split())
graph = []
for _ in range(n):
graph.append(list(map(int, input().strip())))
# r d l u
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
result = 0
que = queue.Queue()
def bfs(y, x):
que.put((y,x))
while not que.empty():
if not que.empty():
qy, qx = que.get()
for i in range(4):
gy = qy+dy[i]
gx = qx+dx[i]
if 0 <= gy < n and 0 <= gx < m:
if graph[gy][gx] == 1:
que.put((gy, gx))
graph[gy][gx] = graph[qy][qx] + 1
return graph[n-1][m-1]
print(bfs(0,0))시간은 데크가 더 빠르다 !

추가
처음, 큐에 (y값, x값, 이동횟수) 3개의 데이터를 넣고 문제를 풀었는데, 시간초과 결과가 나왔다.
위 경우, 방문 했던 노드를 0으로 바꾸기의 로직과 큐 안의 자료구조의 데이터가 3개인 것 만 다르다.
시간제한이 빡빡하거나, 내가 모르는 무언가 있지 않을까 싶다...
또한, 이차원 리스트를 인풋으로 받을 때 아래와 같이 사용함을 외워야겠다.
for _ in range(n):
graph.append(list(map(int, input().strip())))'코딩테스트' 카테고리의 다른 글
| [백준] 10815번 : 숫자 카드 - 파이썬 (0) | 2023.03.28 |
|---|---|
| [백준] 14497번 : 주난의 난 - 파이썬 (0) | 2023.03.23 |
| [백준] 17609번 : 회문 - 파이썬 (0) | 2023.03.19 |
| [백준] 10799번 : 쇠막대기 - 파이썬 (0) | 2023.03.16 |
| [백준] 9012번 : 막대 - 파이썬 (0) | 2023.03.08 |



